Using the Python scripts in the Code folder Part 1
25/01/12 11:33 Filed in: Info
Here is just a brief introduction to the basic Python 3.x scripts to get a token list, the type-token ratio, a frequency profile and unique token lists from a set of documents. We presuppose that you have some common OS on your computer, some version of Python 3.x installed, and that you have access to a command line tool.
Basic Settings
I assume that you are familiar with the command line tool on Mac, Windows (PowerShell) or Linux. Check out these tutorials for the specific platforms:
Linux
Mac
Windows
There are many video tutorials for all of these tools on YouTube and elsewhere.
I also assume that you have installed Python 3 from either Python.org or ActiveState.com on your OS and that it is running correctly. On Windows you might need to set the global path to the Python folder in the system’s PATH variable. See here for instructions on how to do that, i.e. you would presumably add C:/Python32/ separated by a semicolon ; to the PATH variable (assuming that this is, where your Python 3 was installed). It might also be that your Python 3 binary executable is not called python3.exe, but just python.exe. In this case you would replace in the following commands python3 with simply python.
Download the code-archive and unpack it somewhere, or use the code in the Code folder of the course on Dropbox.
Tokenizing Text Files
The Python 3 code in tokenizer.py reads the text from all the files given as parameters and returns a list of tokens. This is a very simplified tokenizer that does not check for acronyms or abbreviations, or any other issues related to the disambiguation of for example the apostrophe or period. A collection of raw text-files can be tokenized by providing the files as individual parameters:
python3 tokenizer.py mytext1.txt mytext2.txt
or by using wildcards (all files with a name that ends in .txt):
python3 tokenizer.py *.txt
If you want to process all text files in our Corpus folder and you are in the Corpus folder, where the tokenizer.py code is located, you can use the following command line:
python3 tokenizer.py ../Corpora/*.txt
The output of the tokenizer is a list of tokens, one token per line, as shown in the following selection:
On
Saturday
,
they
finally
got
to
show
what
they
believe
they
can
be
:
the
If you want to save the token list to a file, you can redirect the output from the screen (or command line or console window) to a file by using the redirect symbol > and a file name for the output file:
python3 tokenizer.py ../Corpora/*.txt > token-list.txt
This will generate a text file token-list.txt in your current folder that contains the tokens in the linear order as processed by going through the text files in the Corpus folder.
Calculating the Type/Token Ratio
The code in ttr.py will give you the type-token ratio for a token list, as generated by tokenizer.py. You can call it with a list of file names as the parameter, where the files contain the tokens, for example organized line-by-line. In the Corpus folder I piped out the tokenizer.py output to sports.lst, tech.lst etc. files. This is the way one can now get the type-token ratio from these token lists:
python3 ttr.py ../Corpora/sports.lst ../Corpora/tech.lst
The output should look like:
Type/Token ratio for ../Corpora/sports.lst : 24.30373991133341
Type/Token ratio for ../Corpora/tech.lst : 23.697794462693572
Frequency Profiles
To generate a frequency profile from the token lists, you can use the fp.py code and provide as a parameter the file names of the files that contain the tokens or token lists (one or more such files):
python3 fp.py ../Corpora/sports.lst
The resulting output should look like this selection:
Eastern 1
revealed 1
priority 1
their 17
Odom 3
ankle 2
man 7
final 3
Association 3
testing 1
completed 2
exactly 2
slider 1
regards 1
Bolton 4
haven 1
coughed 1
bid 1
pointers 2
thrashing 1
limiting 1
decided 2
Najar 1
The tokens are printed out, followed by a TAB-delimiter and the absolute frequency of the corresponding token. If you want to store the frequency profile in a file, you can redirect the output this way:
python3 fp.py ../Corpora/sports.lst > sports-fp.txt
The file sports-fp.txt will contain the token-frequency tuples line-by-line, and can as such be imported into Microsoft Excel or Calc (OpenOffice) for further processing or analysis.
In Microsoft Excel for example open a new workbook and select in the menu Data > Get External Data > Import Text File… s shown in the following image:
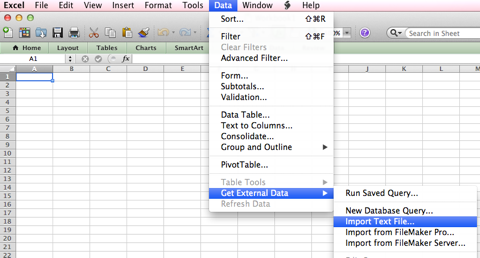
Select the file sports-fp.txt, if you generated it as shown above, and the following wizard window should show up:
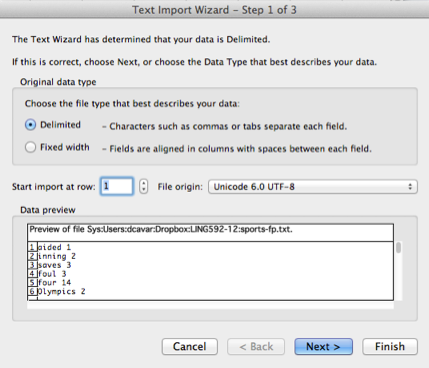
Here we can select also the File origin. Since we use UTF-8 formatted text files per default, the best choice is to select Unicode 6.0 UTF-8 as the origin. Continue with “Next”, and the preview should show you the correct split of the cell-content on the TAB-delimiter in the frequency-profile text file:
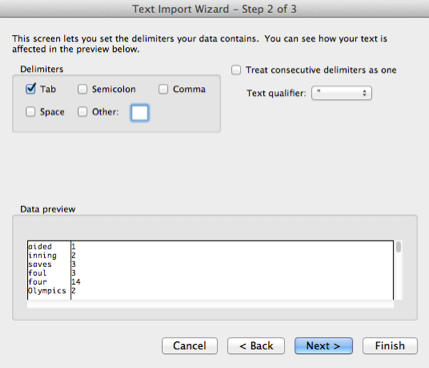
You can select a column and specify a data format for it, as for example for the token column a Text data format in the following snapshot:
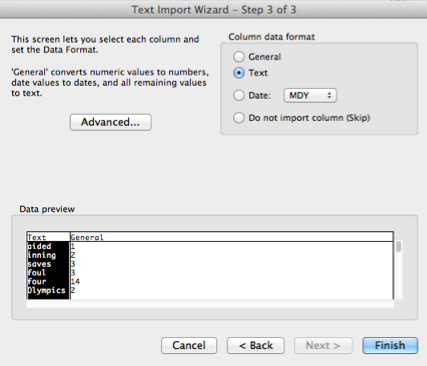
Select Finish and in the following Import dialog either leave the default or specify a new range or sheet into which the data will be imported:
After a successful import you should see the following data in your table:
You can label the columns now, sort over the tokens or the frequency to generate alphabetical frequency tables, or increasing or decreasing frequency profiles.
The code in fp.py will generate you a frequency profile with absolute frequencies. If you would like to get the frequency profile with relative frequencies, use rfp.py as:
python3 rfp.py ../Corpora/sports.lst > sports-rfp.txt
The content of the output file sports-rfp.txt should contain line-by-line TAB-separated tokens and their corresponding relative frequency, given the token list sports.lst:
aided 0.00011367511651699443
inning 0.00022735023303398886
saves 0.0003410253495509833
foul 0.0003410253495509833
four 0.001591451631237922
Olympics 0.00022735023303398886
controversial 0.00011367511651699443
hanging 0.00011367511651699443
captain 0.0003410253495509833
defraud 0.00011367511651699443
poorly 0.00011367511651699443
whose 0.0003410253495509833
replacements 0.00011367511651699443
Vince 0.00011367511651699443
Casey 0.00011367511651699443
Doucet 0.00011367511651699443
opener 0.0003410253495509833
under 0.0010230760486529499
sputter 0.00011367511651699443
Personable 0.00011367511651699443
League 0.0003410253495509833
Brek 0.00011367511651699443
regional 0.00011367511651699443
every 0.0003410253495509833
updates 0.00011367511651699443
This data can of course be imported in a spreadsheet program as described above for Microsoft Excel.
I assume that you are familiar with the command line tool on Mac, Windows (PowerShell) or Linux. Check out these tutorials for the specific platforms:
Linux
- Using the Terminal (Ubuntu)
- on Youtube (and many more there): Introduction to the Terminal
Mac
Windows
- Windows PowerShell
- What Can I Do With Windows PowerShell?
- Some more links on the PowerShell Tutorials page
There are many video tutorials for all of these tools on YouTube and elsewhere.
I also assume that you have installed Python 3 from either Python.org or ActiveState.com on your OS and that it is running correctly. On Windows you might need to set the global path to the Python folder in the system’s PATH variable. See here for instructions on how to do that, i.e. you would presumably add C:/Python32/ separated by a semicolon ; to the PATH variable (assuming that this is, where your Python 3 was installed). It might also be that your Python 3 binary executable is not called python3.exe, but just python.exe. In this case you would replace in the following commands python3 with simply python.
Download the code-archive and unpack it somewhere, or use the code in the Code folder of the course on Dropbox.
Tokenizing Text Files
The Python 3 code in tokenizer.py reads the text from all the files given as parameters and returns a list of tokens. This is a very simplified tokenizer that does not check for acronyms or abbreviations, or any other issues related to the disambiguation of for example the apostrophe or period. A collection of raw text-files can be tokenized by providing the files as individual parameters:
python3 tokenizer.py mytext1.txt mytext2.txt
or by using wildcards (all files with a name that ends in .txt):
python3 tokenizer.py *.txt
If you want to process all text files in our Corpus folder and you are in the Corpus folder, where the tokenizer.py code is located, you can use the following command line:
python3 tokenizer.py ../Corpora/*.txt
The output of the tokenizer is a list of tokens, one token per line, as shown in the following selection:
On
Saturday
,
they
finally
got
to
show
what
they
believe
they
can
be
:
the
If you want to save the token list to a file, you can redirect the output from the screen (or command line or console window) to a file by using the redirect symbol > and a file name for the output file:
python3 tokenizer.py ../Corpora/*.txt > token-list.txt
This will generate a text file token-list.txt in your current folder that contains the tokens in the linear order as processed by going through the text files in the Corpus folder.
Calculating the Type/Token Ratio
The code in ttr.py will give you the type-token ratio for a token list, as generated by tokenizer.py. You can call it with a list of file names as the parameter, where the files contain the tokens, for example organized line-by-line. In the Corpus folder I piped out the tokenizer.py output to sports.lst, tech.lst etc. files. This is the way one can now get the type-token ratio from these token lists:
python3 ttr.py ../Corpora/sports.lst ../Corpora/tech.lst
The output should look like:
Type/Token ratio for ../Corpora/sports.lst : 24.30373991133341
Type/Token ratio for ../Corpora/tech.lst : 23.697794462693572
Frequency Profiles
To generate a frequency profile from the token lists, you can use the fp.py code and provide as a parameter the file names of the files that contain the tokens or token lists (one or more such files):
python3 fp.py ../Corpora/sports.lst
The resulting output should look like this selection:
Eastern 1
revealed 1
priority 1
their 17
Odom 3
ankle 2
man 7
final 3
Association 3
testing 1
completed 2
exactly 2
slider 1
regards 1
Bolton 4
haven 1
coughed 1
bid 1
pointers 2
thrashing 1
limiting 1
decided 2
Najar 1
The tokens are printed out, followed by a TAB-delimiter and the absolute frequency of the corresponding token. If you want to store the frequency profile in a file, you can redirect the output this way:
python3 fp.py ../Corpora/sports.lst > sports-fp.txt
The file sports-fp.txt will contain the token-frequency tuples line-by-line, and can as such be imported into Microsoft Excel or Calc (OpenOffice) for further processing or analysis.
In Microsoft Excel for example open a new workbook and select in the menu Data > Get External Data > Import Text File… s shown in the following image:
Select the file sports-fp.txt, if you generated it as shown above, and the following wizard window should show up:
Here we can select also the File origin. Since we use UTF-8 formatted text files per default, the best choice is to select Unicode 6.0 UTF-8 as the origin. Continue with “Next”, and the preview should show you the correct split of the cell-content on the TAB-delimiter in the frequency-profile text file:
You can select a column and specify a data format for it, as for example for the token column a Text data format in the following snapshot:
Select Finish and in the following Import dialog either leave the default or specify a new range or sheet into which the data will be imported:
After a successful import you should see the following data in your table:
You can label the columns now, sort over the tokens or the frequency to generate alphabetical frequency tables, or increasing or decreasing frequency profiles.
The code in fp.py will generate you a frequency profile with absolute frequencies. If you would like to get the frequency profile with relative frequencies, use rfp.py as:
python3 rfp.py ../Corpora/sports.lst > sports-rfp.txt
The content of the output file sports-rfp.txt should contain line-by-line TAB-separated tokens and their corresponding relative frequency, given the token list sports.lst:
aided 0.00011367511651699443
inning 0.00022735023303398886
saves 0.0003410253495509833
foul 0.0003410253495509833
four 0.001591451631237922
Olympics 0.00022735023303398886
controversial 0.00011367511651699443
hanging 0.00011367511651699443
captain 0.0003410253495509833
defraud 0.00011367511651699443
poorly 0.00011367511651699443
whose 0.0003410253495509833
replacements 0.00011367511651699443
Vince 0.00011367511651699443
Casey 0.00011367511651699443
Doucet 0.00011367511651699443
opener 0.0003410253495509833
under 0.0010230760486529499
sputter 0.00011367511651699443
Personable 0.00011367511651699443
League 0.0003410253495509833
Brek 0.00011367511651699443
regional 0.00011367511651699443
every 0.0003410253495509833
updates 0.00011367511651699443
This data can of course be imported in a spreadsheet program as described above for Microsoft Excel.